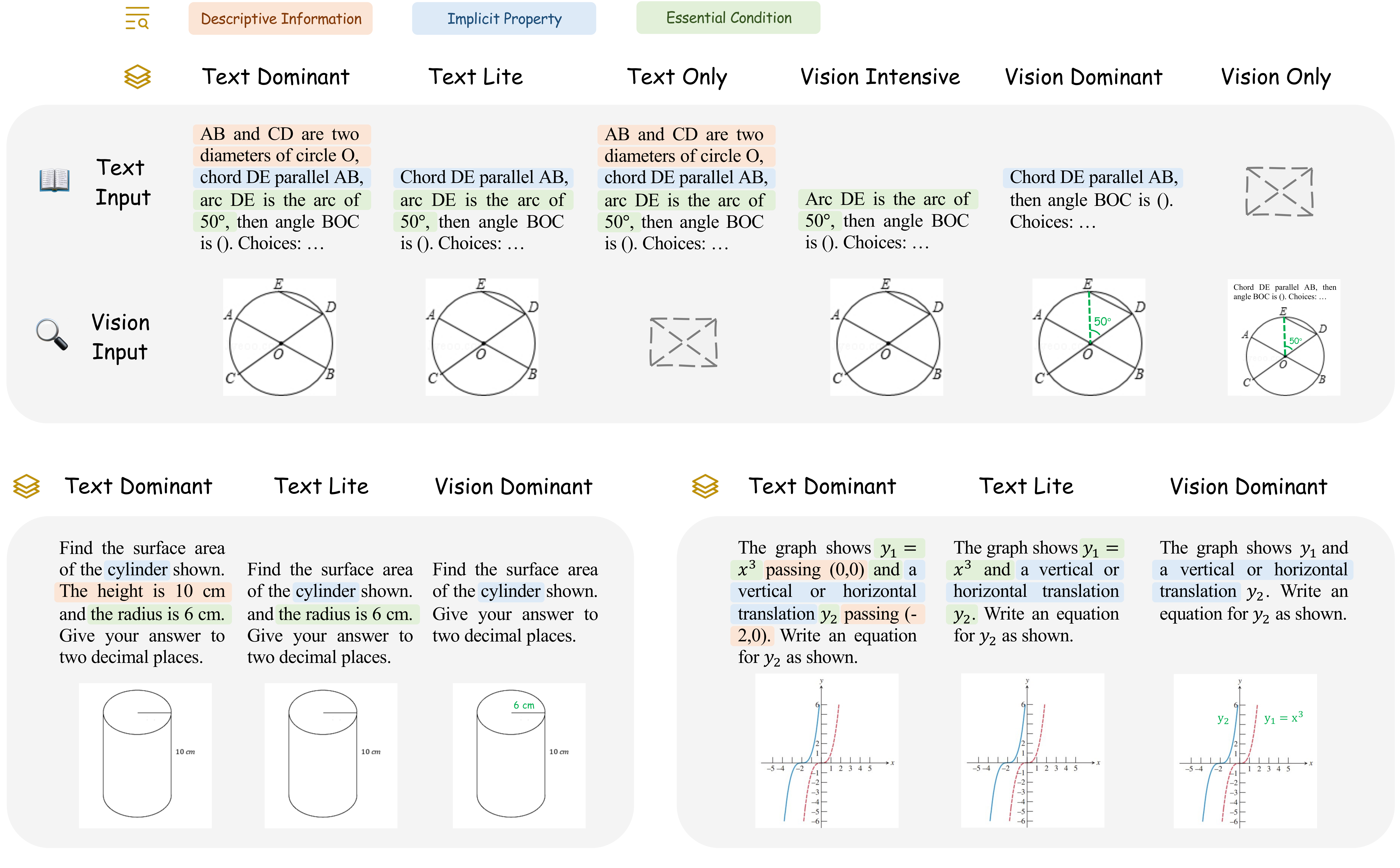
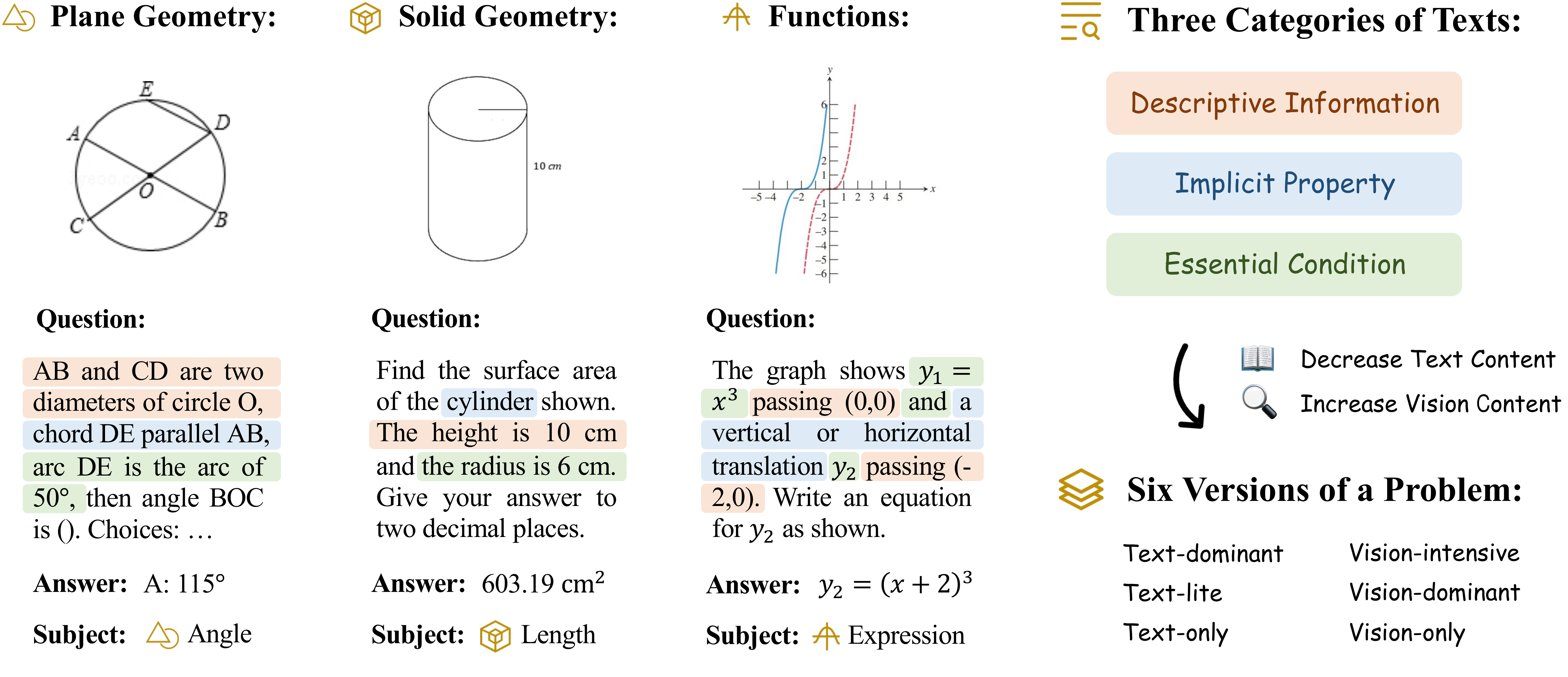
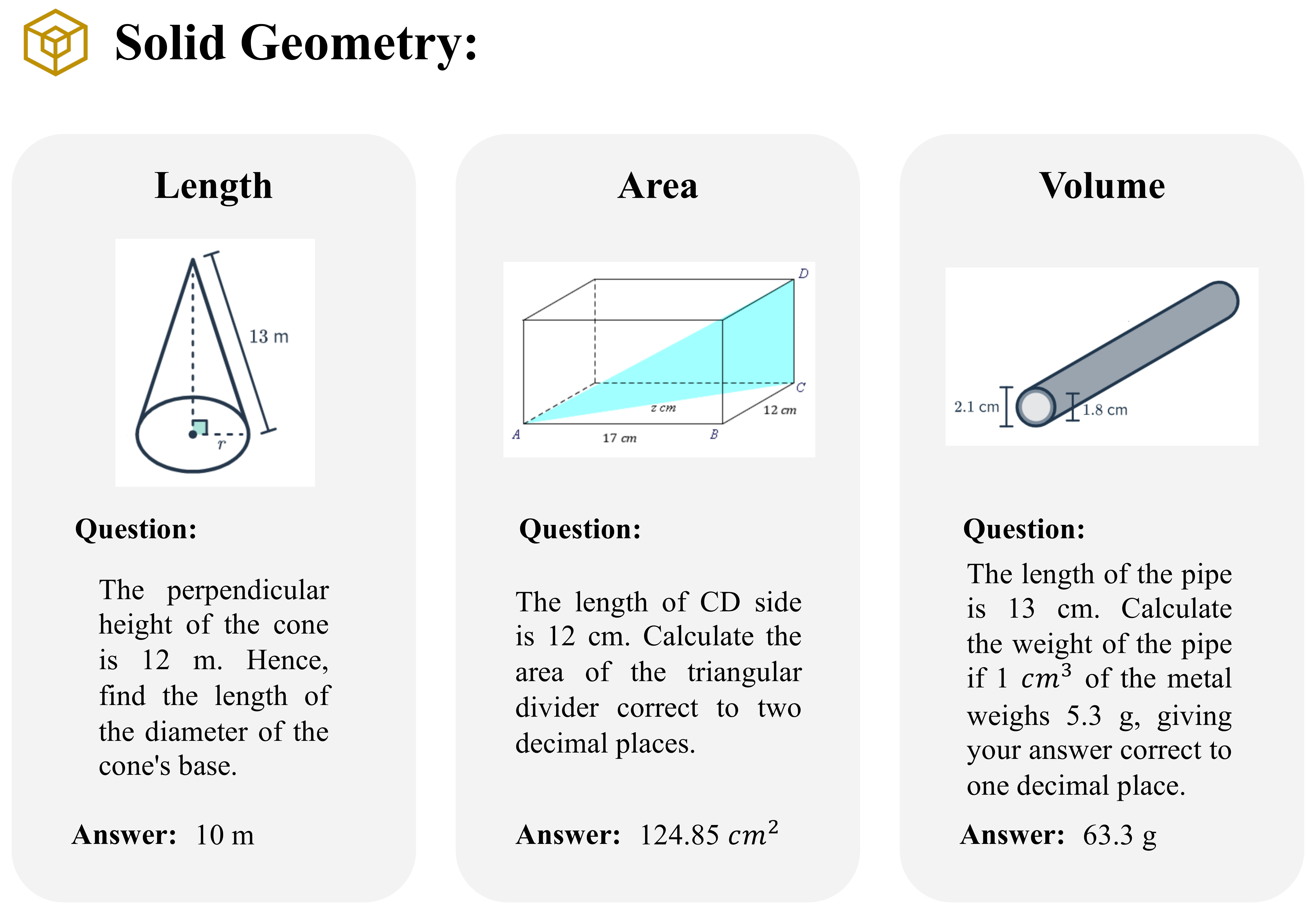
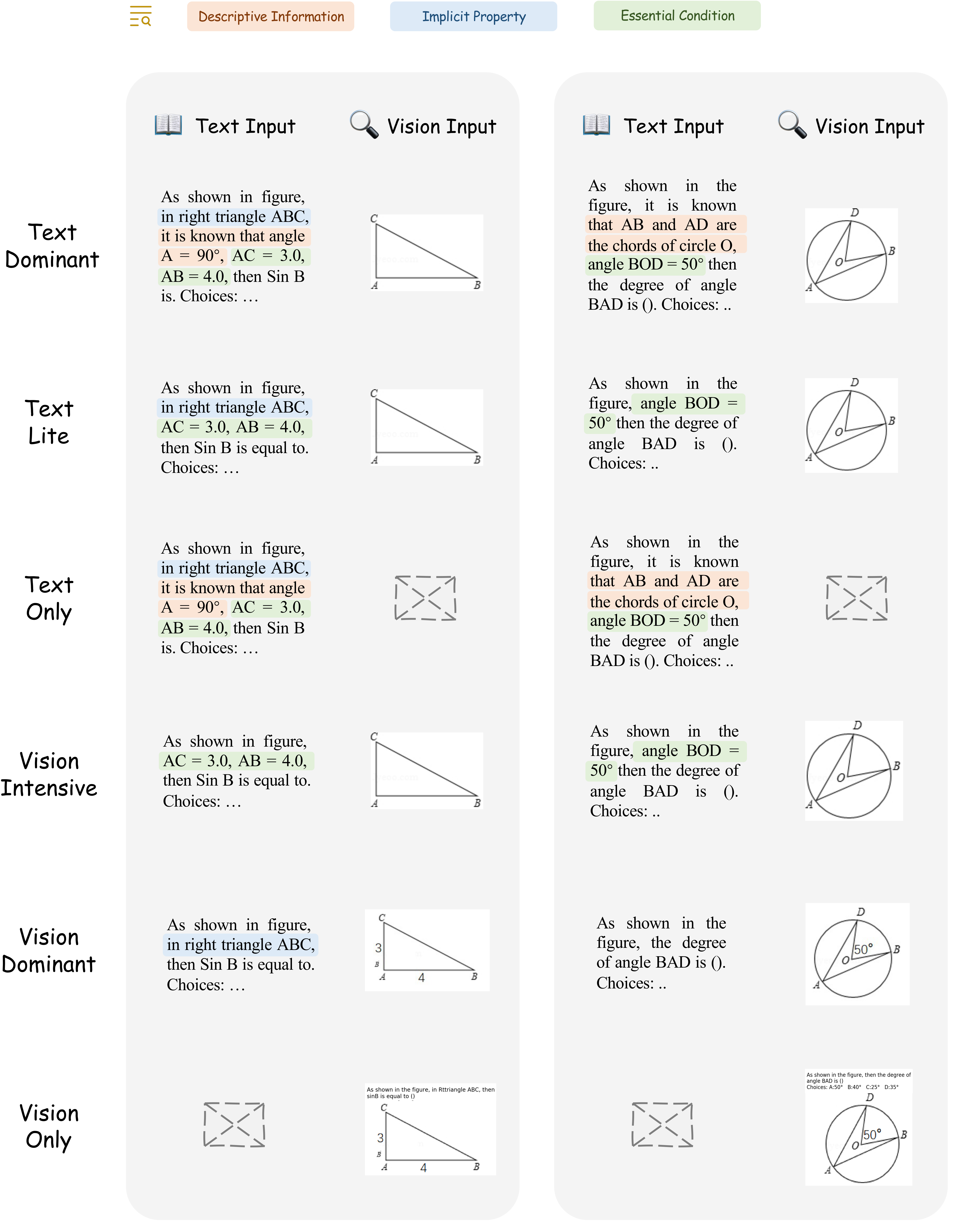
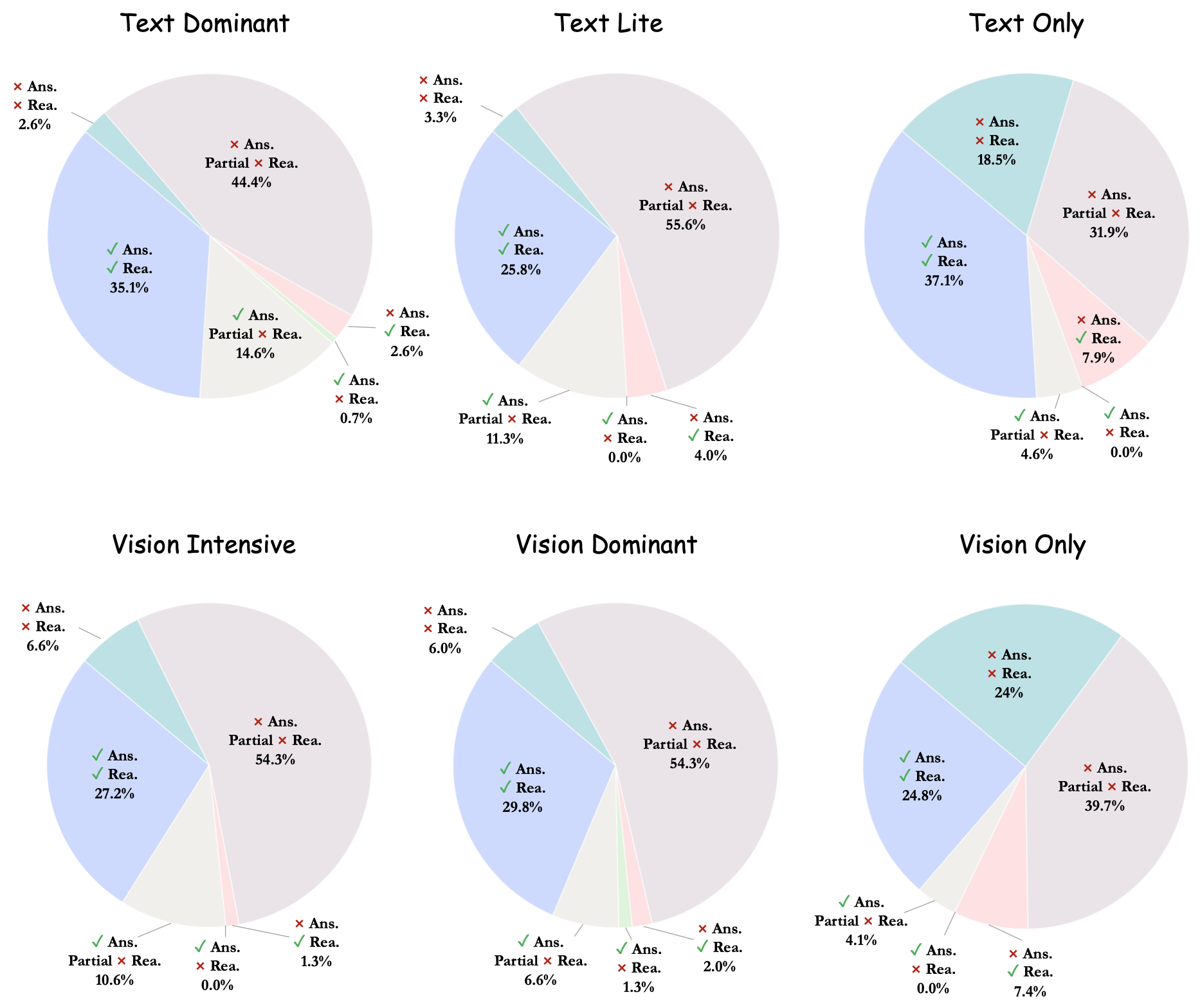
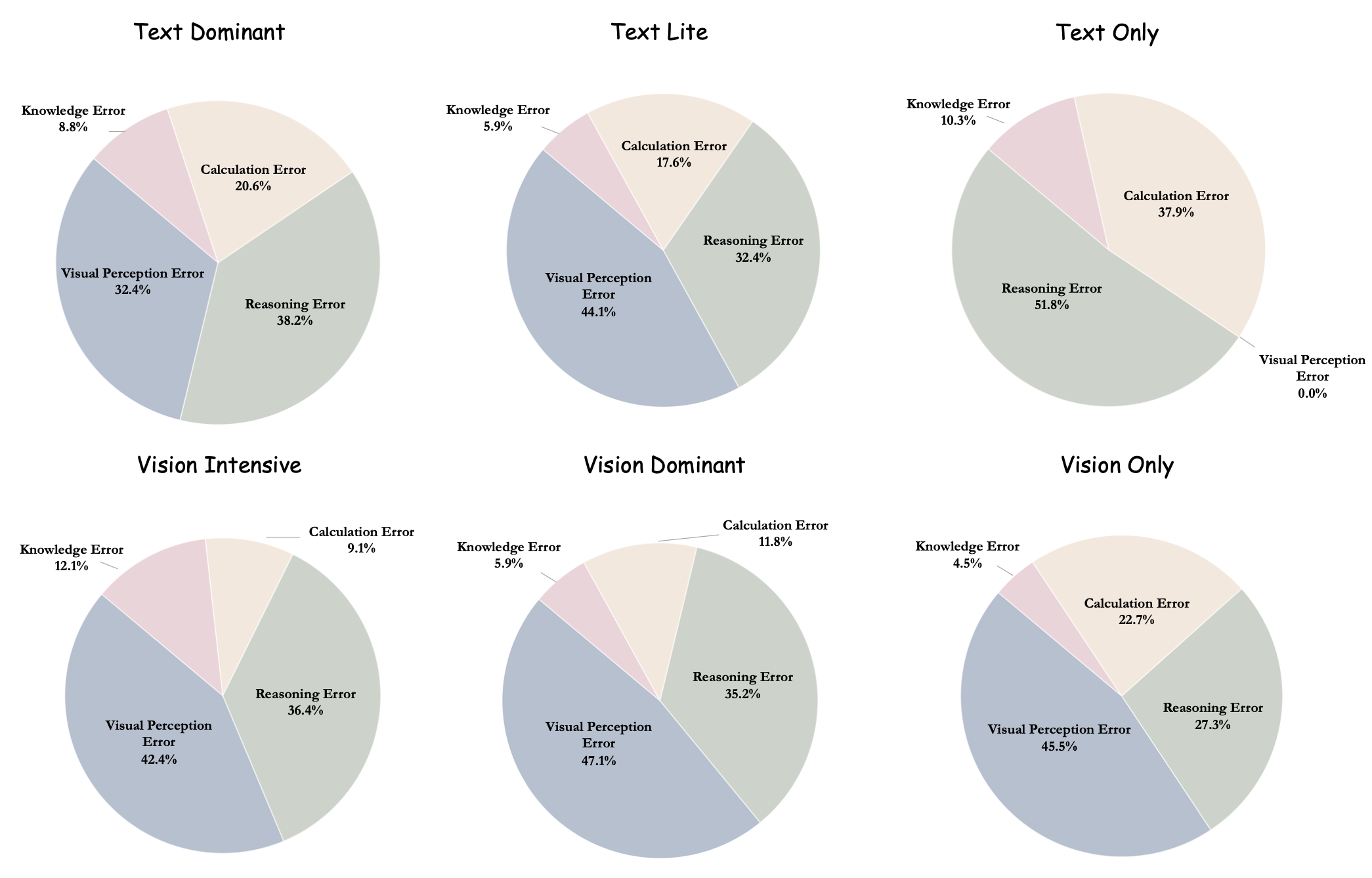
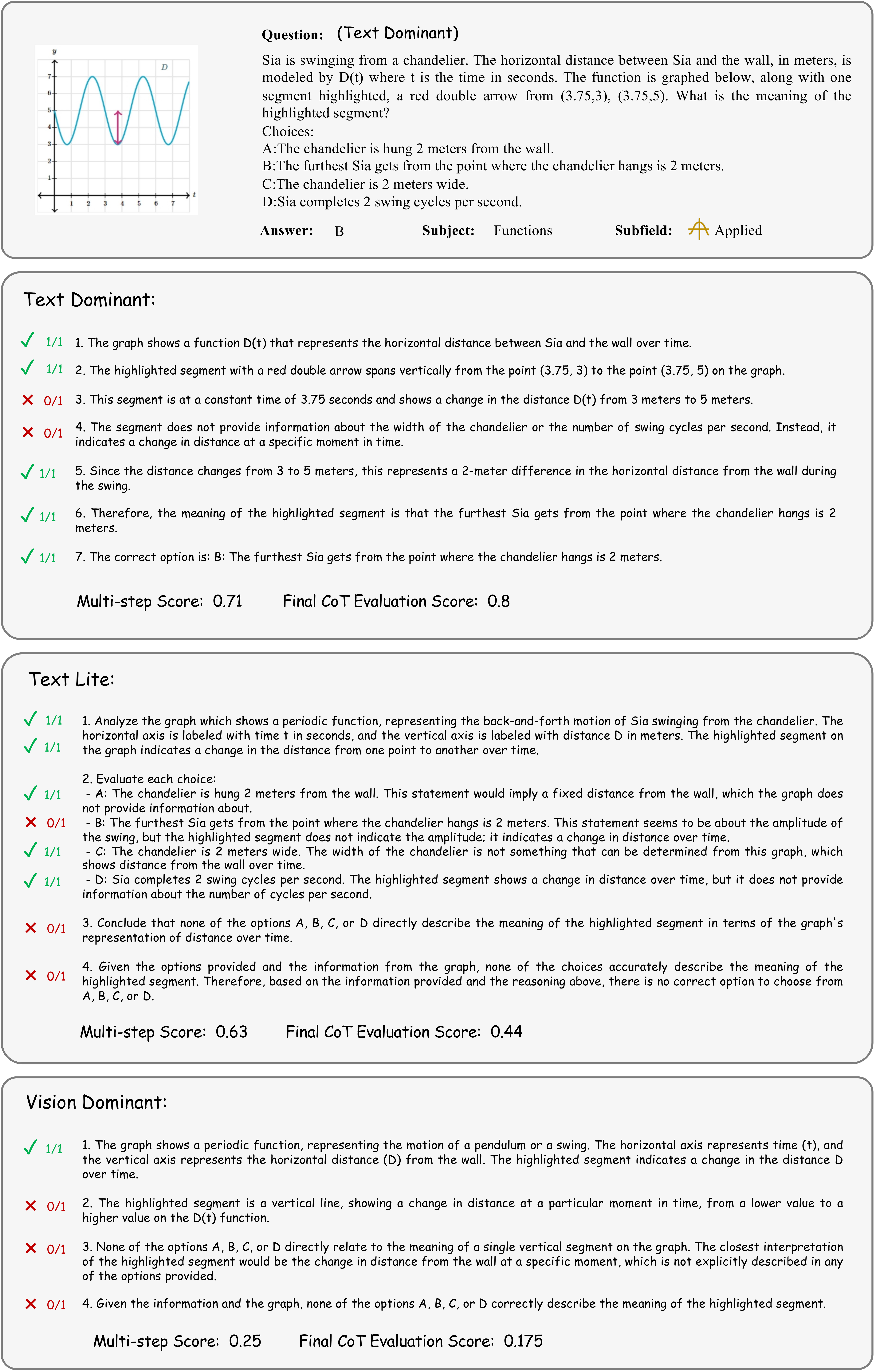
Accuracy scores on the testmini subset of  MathVerse.
MathVerse.
| # | Model | Method | Source | Date | ALL | Text Dominant |
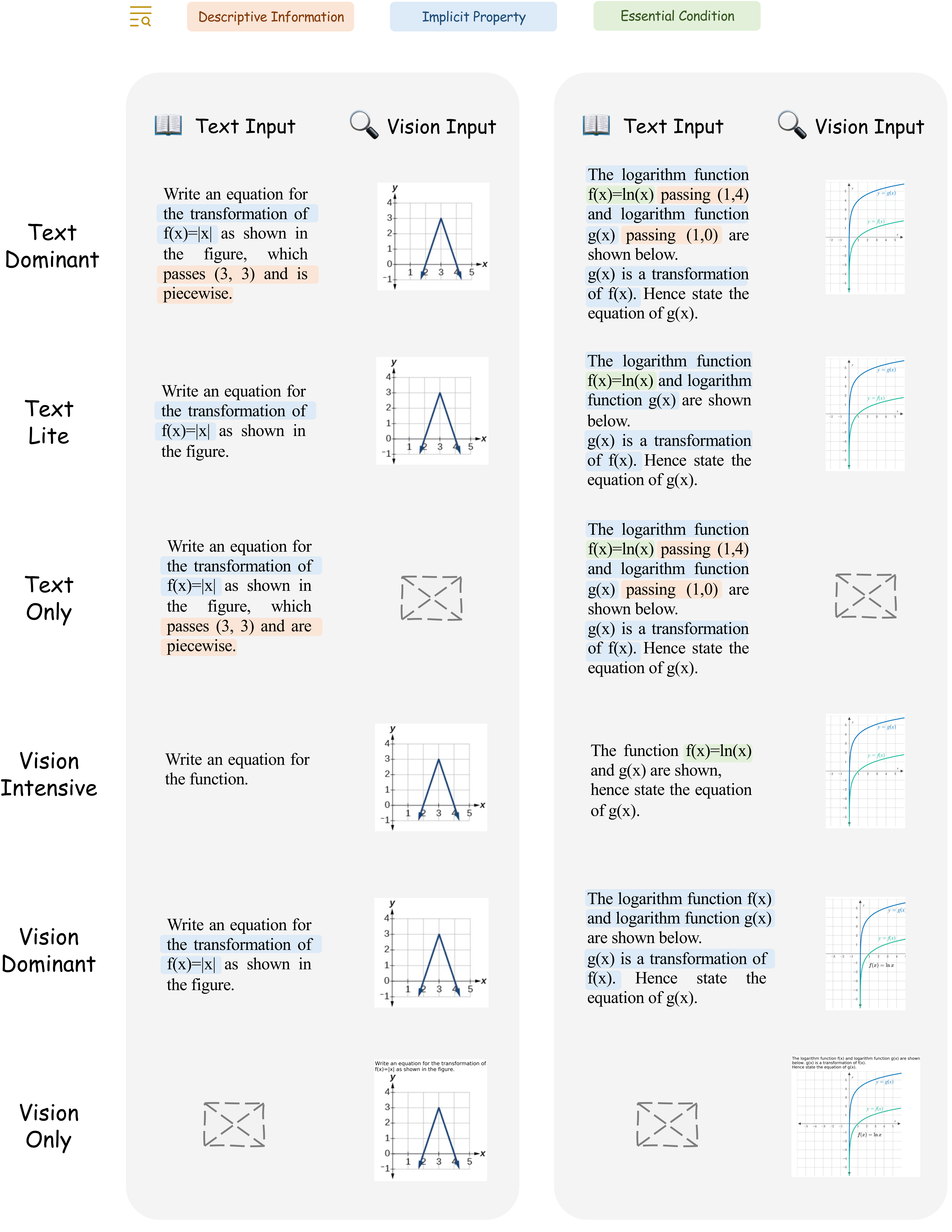
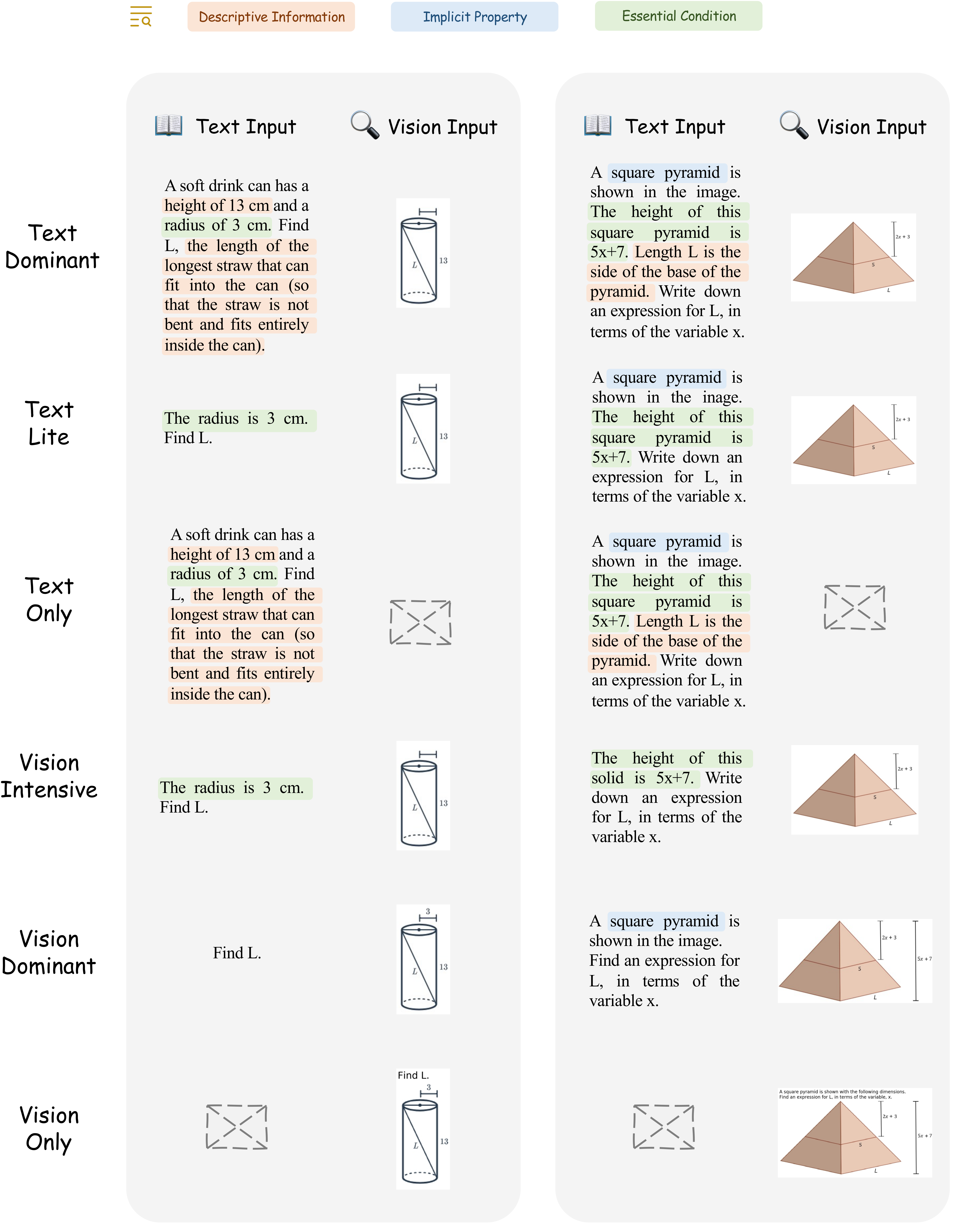
Text Lite |
Text Only |
Vision Intensive |
Vision Dominant |
Vision Only |
|||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CoT-E | w/o | CoT-E | w/o | CoT-E | w/o | CoT-E | w/o | CoT-E | w/o | CoT-E | w/o | CoT-E | w/o | |||||
| 1 | VL-Rethinker-72B | MLLM 🖼️ | Link | 2025-04-10 | - | 61.7 | - | - | - | - | - | - | - | - | - | - | - | - |
| 2 | VL-Rethinker-7B | MLLM 🖼️ | Link | 2025-04-10 | - | 54.2 | - | - | - | - | - | - | - | - | - | - | - | - |
| 3 | GPT-4V | MLLM 🖼️ | Link | 2023-12-26 | 54.4 | 39.4 | 63.1 | 54.7 | 56.6 | 41.4 | 60.3 | 48.7 | 51.4 | 34.9 | 50.8 | 34.4 | 50.3 | 31.6 |
| 4 | Qwen-VL-Max | MLLM 🖼️ | Link | 2023-12-26 | 37.2 | 25.3 | 42.8 | 30.7 | 37.7 | 26.1 | 47.9 | 28.9 | 33.6 | 24.1 | 35.9 | 24.1 | 35.9 | 21.4 |
| 5 | LLaVA-NeXT-34B | MLLM 🖼️ | Link | 2024-01-30 | 34.6 | 23.8 | 49.0 | 33.8 | 37.6 | 25.5 | 30.1 | 21.3 | 35.2 | 23.5 | 28.9 | 20.3 | 22.4 | 15.7 |
| 6 | Gemini-Pro | MLLM 🖼️ | Link | 2023-12-26 | 35.3 | 23.5 | 39.8 | 26.3 | 34.7 | 23.5 | 44.5 | 27.3 | 32.0 | 23.0 | 36.8 | 22.3 | 33.3 | 22.2 |
| 7 | G-LLaVA-13B | MLLM 🖼️ | Link | 2023-12-26 | 16.4 | 16.9 | 23.6 | 21.2 | 18.9 | 20.9 | 22.6 | 22.3 | 17.1 | 17.7 | 13.5 | 14.8 | 8.9 | 10.0 |
| 8 | G-LLaVA-7B | MLLM 🖼️ | Link | 2023-12-26 | 15.7 | 16.6 | 22.2 | 20.9 | 20.4 | 20.7 | 21.6 | 21.1 | 16.5 | 17.2 | 12.7 | 14.6 | 6.6 | 9.4 |
| 9 | InternLM-XComposer2-VL-7B | MLLM 🖼️ | Link | 2024-01-22 | 25.9 | 16.5 | 36.9 | 22.3 | 28.3 | 17.0 | 42.5 | 16.5 | 20.1 | 15.7 | 24.4 | 16.4 | 19.8 | 11.0 |
| 10 | LLaVA-NeXT-13B | MLLM 🖼️ | Link | 2024-01-13 | 17.2 | 15.6 | 21.6 | 19.4 | 19.7 | 15.2 | 25.1 | 18.1 | 17.6 | 16.8 | 14.9 | 15.2 | 12.1 | 11.3 |
| 11 | SPHINX-MoE | MoE 🤖 | Link | 2023-10-03 | 22.8 | 15.0 | 33.3 | 22.2 | 21.9 | 16.4 | 40.7 | 18.3 | 21.1 | 14.8 | 19.6 | 12.6 | 18.3 | 9.1 |
| 12 | ShareGPT4V-13B | MLLM 🖼️ | Link | 2023-12-26 | 17.4 | 13.1 | 21.8 | 16.2 | 20.6 | 16.2 | 14.6 | 6.6 | 18.6 | 15.5 | 16.2 | 13.8 | 9.7 | 3.7 |
| 13 | SPHINX-Plus | MLLM 🖼️ | Link | 2023-12-26 | 14.0 | 12.2 | 16.3 | 13.9 | 12.8 | 11.6 | 15.8 | 14.9 | 12.9 | 11.6 | 14.7 | 13.5 | 13.2 | 10.4 |
| 14 | Qwen-VL-Plus | MLLM 🖼️ | Link | 2023-12-26 | 21.3 | 11.8 | 26.0 | 15.7 | 21.2 | 11.1 | 25.2 | 14.5 | 18.5 | 9.0 | 19.1 | 13.0 | 21.8 | 10.0 |
| 15 | MiniGPT-v2-7B | MLLM 🖼️ | Link | 2023-12-26 | 10.9 | 11.0 | 13.2 | 12.1 | 12.7 | 12.0 | 15.3 | 11.7 | 11.1 | 13.1 | 11.3 | 10.3 | 6.4 | 7.4 |
| 16 | ImageBind-LLM | MLLM 🖼️ | Link | 2023-12-26 | 10.0 | 9.2 | 13.2 | 11.4 | 11.6 | 11.3 | 12.9 | 11.7 | 9.8 | 8.9 | 11.8 | 11.2 | 3.5 | 3.4 |
| 17 | LLaVA-1.5-13B | MLLM 🖼️ | Link | 2023-12-26 | 12.7 | 7.6 | 17.1 | 8.8 | 12.0 | 7.6 | 22.6 | 11.5 | 12.6 | 7.4 | 12.7 | 7.4 | 9.0 | 6.9 |
| 18 | mPLUG-Owl2-7B | MLLM 🖼️ | Link | 2023-12-26 | 10.3 | 5.9 | 11.6 | 6.6 | 11.4 | 6.3 | 13.8 | 6.1 | 11.1 | 6.3 | 9.4 | 5.6 | 8.0 | 4.9 |
| 19 | LLaMA-Adapter V2 | MLLM 🖼️ | Link | 2023-12-26 | 5.8 | 5.7 | 7.8 | 6.2 | 6.3 | 5.9 | 3.9 | 2.7 | 6.2 | 6.1 | 4.5 | 4.2 | 4.4 | 6.1 |
| - | ChatGPT | LLM 📄 | Link | 2023-10-03 | - | - | 51.3 | 33.3 | 38.5 | 18.9 | 51.3 | 33.3 | - | - | - | - | - | - |
| - | GPT-4 | LLM 📄 | Link | 2023-10-03 | - | - | 63.4 | 46.5 | 40.7 | 20.7 | 63.4 | 46.5 | - | - | - | - | - | - |
| - | Human Performance* | - | Link | 2023-10-03 | - | 64.9 | - | 71.2 | - | 70.9 | - | 41.7 | - | 61.4 | - | 68.3 | - | 66.7 |
| - | Random Chance | - | Link | 2023-10-03 | - | 12.4 | - | 12.4 | - | 12.4 | - | 12.4 | - | 12.4 | - | 12.4 | - | 12.4 |
Method types: MLLM 🖼️: Multi-modal Large Language Model, MoE 🤖: Mixture of Experts, LLM 📄: Large Language Model